Slides from 2020 conference that eventually became this paper
Slides from 2020 conference that eventually became this paper
Slides located here.

John and Marcia were very generous with their embarrassment of stored media riches. I gave them a copy of Neighborhood Rhythms, and they filled a paper shopping bag with some of John’s and his friends’ work from over the years — poets working in and around the Los Angeles from the 1960s onwards. I’m only now getting through it.
One of the works they gave me is a beautiful collection by a poet named William Pillin. I’m reproducing one of its poems, Sabbath, at the end of this post.
As we move away from stored media, will we also move away from the cull and share cycle that came along with them? Or is there a way to share the metadata of our digital files that does the same?
We can stick with DRM, but it would be nice to have a universal standard (don’t laugh) for a digital library. There’s no reason the metadata of the media we own have to be encrypted, even if some of the content does.
SabbathNot the prescribed movement of hands, not the ritual whispers out of antique books with broken bindings, not those you left me, people of blessed candles, but a certain music, a secret between us, so that even I, a pagan in Babylon, celebrate the Creation's completion. I can spare but a few hours for this evening's silence as I can't afford a whole day without labor; and the hymns I sing are alas, not Zemirot, the Sabbath hymns, but snatches of Handel, an Anglican rabbi; but I will praise the Indwelling Glory, putting, however briefly, my trials behind me, putting, however briefly, Egypt behind me. I will not stint, I will provide of the finest. The floors will be scrubbed, the furniture polished. With choice meat and hallot I will praise Thee, aye, with a double portion of manna, with broiled fish, with a goblet of brandy. Overlook therefore the profane, the informal. Send Shabbath Shalom, the peace of the evening, to us who are doing their ignorant best at this altar; son, wife and husband basking at twilight in the tender effulgence of grandmother's candles.
I'm glad I collected wood first thing this morning. #SnowDay pic.twitter.com/6DgHewZ1b3
— Darren Abramson (@DarrenAbramson) March 26, 2014
@fryselectronics should those all say PST? #BlackFriday pic.twitter.com/qVMK0SanyA
— Darren Abramson (@DarrenAbramson) November 29, 2013
See image below:
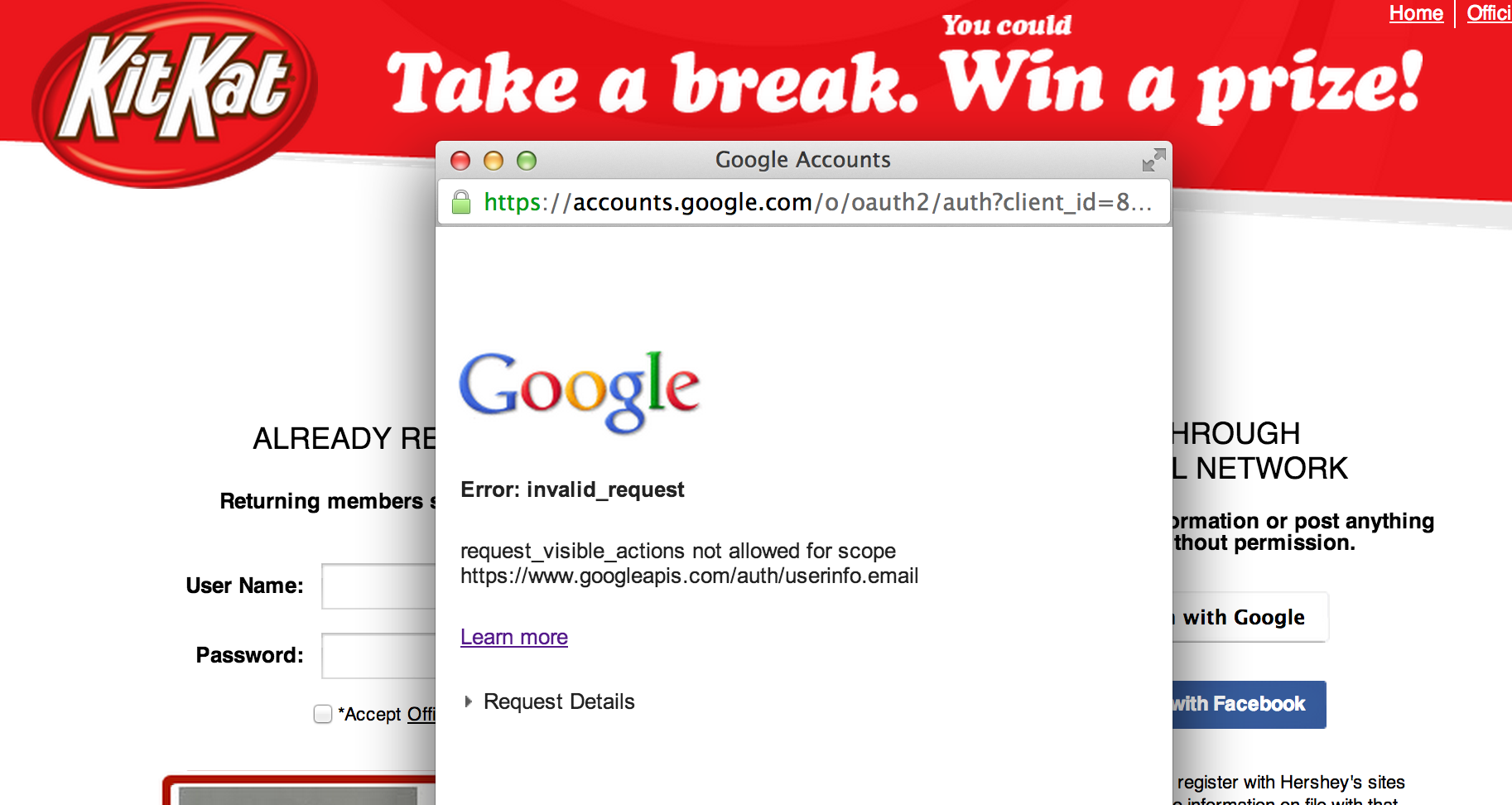
UPDATE:
something happened. Google+ is now super cozy with WordPress. The Sep. 2013 update includes the functionality described below, and lets folks comment using Google+ authentication. Hurray!
****************
Short answer:
“At present Google+ API (released in September 2011) provides read-only access to public data, hence posts only go one way.”
If you read the reviews for the hacky WP extension mentioned there, you discover that it’s totally broken. In the words of a reviewer as of April 2013,
“This worked one time, several months ago, and since then has failed every time. This may not be the fault of the developer, but of Google, who closed the option to post that was exploited by this plugin (not positive that’s the case, but it DID work one time for me).”
Wuh?
There are tons of elegant plugins, with full API support for pushing WP content to your Facebook profile. Isn’t this a barrier to Google+ adoption, or at least a drag on its traction? Or is the Google juggernaut powerful enough to get people to post there natively/manually?
 The guy behind Primer has done it again.
The guy behind Primer has done it again.
If you haven’t seen it, it’s on Netflix — there’s no excuse.
Unlike the idiot reviews that make it sound as if this film is an impressionist painting, all about relativized subjective reflection, this film is chronologically linear. Even the dream sequences are literal, just sometimes internal, or small-scale. From an interview with actor/director/producer/writer/cinematographer/lighting director/etc./etc Shane Carruth:
Piecing together this story takes work. Carruth is good with that.
“My favourite film experience is one that really requires a conversation to really get into what we saw,” he says.
I don’t want to spoil it, but the film is exactly equal parts Prometheus and Eternal Sunshine of the Spotless Mind. Exactly.
What? You don’t agree? What about that ending? And the life cycles of parasites? Let’s agree to disagree.
There’s so many themes in here that it’s hard to navigate them all. One that I’m interested in is an argument that treating mental illnesses entirely as a pathology subject to medical interventions creates two negative outcomes:
Another thing I find interesting is the claim that people can be good at many different things, and express virtues in some but not others. We get a vision that I associate with Paul Johnson’s Intellectuals, of the obsessive artist/scientist who achieves excellence, but ruthlessly manipulates those around them to support their endeavours. So far as I can tell, every major character falls under this type. I think we’re also asked, as I remember Johnson doing, whether we’re all better off having such folks around. Certainly the film suggests positive outcomes unattainable without the major artist/villain, but also satisfies a revenge fantasy involving him.
And it’s beautiful, the sound editing is amazing, the acting is great, the script is very well done.


This is a story about a story. Once upon a time a hiphop radio DJ found an old piece of vinyl lying around. That record contained hundreds of snippets of spoken word poetry recording in and around LA in the early 1980s. He had produced a few of his own tracks by the late 90s/early 2000s, and thought it might be neat to sample some of that spoken word stuff for his next couple of recordings. So, around that time, he produced a couple of new tracks. One of them contains the following story, lifted in its entirety from that record he found:
You pick up this working girl, who's hooked on smack, who hustles and scores. "That's all I do," she says. She says, "ten bucks for head, fifteen for half and half." She says, "three hits a day at thirty-five per." You say, "that's seven tricks a day at least." "But," she says, "sometimes I get lucky." "Once this guy gives me a bill and a half just to eat me. Only time I ever came." You figure you can save her. You sell your color TV. That keeps her off the streets a whole day. You hock your typewriter for one jolt. Then your shotgun, your watch. A week later, you say, "listen, I'm a little short." But she says, "no scratch, no snatch." You say, "look, it is better to give." "But," she says, "beat off, creep." One night they spot you on the street in your skivvies, trying to sell your shoes. You tell them who you are, but they nail you. Then she happens by, and she says, "Christ, you look fucked." She says, "hang tough." But you don't say anything. You just think, what a bum rap for a nice, sensitive guy like me.
The name of the track this is on is “You Are Sleeping” by “PQM“, AKA “DJ Prince Quick Mix,” AKA Manuel Napuri. Opinions likely differ as to whether this is an interesting or valuable piece of poetry/prose. However, the Internet attests to the value that many attribute to it. For example, the Discog pages for the various versions of the track contain reviews like the following:
A superb piece of music. I have heard it on several mix albums and also played at several club nights and I never tire of hearing it. The monologue flows perfectly in time with the underlying rhythm, and is more than just the bunch of random samples that is so often used in dance music. The story the dude tells is ultra-seedy, but at the same time also has very humane elements to it. This is an excellent house record. The entire production is tight, clean and grooves from start to finish. The actual vocal samples are what makes this record a must have. That repeated “You Are Sleeping” sample has an acapella which is a good DJ tool and as most PQM productions go, they have nice breakdowns and builds. One of the finest Yoshitoshi records ever made. The meaning of the absurd ironically lyrics has been widely discussed, but that’s the meaning, they are not ment [sic] to be understood in only one way – you gotta check it out yourself. Could be the greatest lyrics ever written for a song, next to Underworld’s Born Slippy.As I’m writing this, YouTube contains versions of the song with over 300,000 views, and such comments as:
These are the greatest words ever spoken in a dance track. The writing, whatever it is from, just makes me cringe in aweThe song has gone on to be played in nightclubs, sold to mix CDs and has been widely appreciated and discussed. It is reasonable to suppose that PQM’s career has benefitted significantly from his track ‘You Are Sleeping.’ A review of the remix release of the track states:
What is this track “You Are Sleeping” all about? “You Are Sleeping” was first released June 2002 and featured the Deephead Pass, Thumpin´ Instrumental, Bonus Beats and DJ Tools. It was tribal drumming workout that was minimal in the inclusion of other samples. But what made it a standout was the bizarre spoken word story told at the breakdown by a man´s experience with picking up a prostitute that hustles to earn money for her smack addiction. He goes on to say he thinks he can save her, ends up selling all his possessions and ends up broke, with her responding to that with “no scratch, no snatch” and leaves him. After recounting being homeless, getting beat up, having the prostitute stroll by and tell him he looks horrible and hang tough, he concludes that it was a bum wrap [sic] for being a nice sensitive guy. (emphasis added)As I write this, there appears to be no evidence available anywhere as to who wrote or spoke the story in the track. Recently I tried to contact PQM through his facebook page to find out who is behind it. I didn’t get any response, and decided to figure it out myself. I’m not the first person to try. The Trance Addict forum, around for over 12 years, has sub-forums dedicated to the identification of tracks and sharing track lists from DJ sets. Electronic music fans can spend lots of time trying to ‘ID’ a track. As you might expect, there’s a long (7 page, right now) thread of people trading notes, trying to identify the spoken word source of You Are Sleeping. You can find people on the Internet speculating that it’s Bukowski, or Burroughs. When I asked some Bukowski fans for help, they suggested in turn that it might be Jesse Bernstein. The only attribution that anyone can find is, as pointed out in the Trance Addict discussion, is listed in the Discogs summary of the liner notes:
Contains a sample from “Hoes Gotta Eat Too” by DJ Xenamorph by courtesy of Abducted Recordings NYC/all rights reserved
This is pretty clearly a joke. There is no such song, and there is no such recording artist. So the attribution has been faked. It’s possible that PQM sampled the record and then lost it, and was encouraged by the label to add something indicating copyright status. If you’ve read this far, you’re probably interested in who it really is. I’ll tell you, just as soon as I explain how I figured it out. Googling snippets of the spoken word itself led nowhere except lyrics sites for You Are Sleeping. After many hours of googling, and trawling through YouTube, I noticed that PQM released another track at around the same time as YAS: “Insane Poem.” The Discogs summary of its liner notes states:
Contains sample from “I’m Waiting For The World To Admit It’s Insane,” by DJ Xenamorph.
That sample includes the following:
I know who's free and I know who's a slave, and I'm waiting for the world to admit it's insane.
It’s reasonable to think that the source for this short snippet might be the same as the one for YAS. When you google this passage with quotations around it, so as to only return exact matches, you find its source: a poem written by Michael C. Ford, dedicated to Henry Rollins. The title of the poem is ‘Ammunition.’ That source says nothing about an audio recording of it, though. But when you google ‘Michael C Ford’ and ‘Ammunition’, some very helpful links are at the top: they refer to a 1984 vinyl double lp of spoken word recordings, including the aforementioned poem dedicated to Henry Rollins. And if you google that record further, you find something beautiful: a personal music blog describing Neighborhood Rhythms (Patter Traffic) and a bit of its history, with a download of all of the tracks. If that link ever breaks, comment here and I’ll repost it. If you listen to all of those tracks, you’ll find the ones that PQM sampled both for YAS and for Insane Poem. The name of the poet who wrote and spoke the lines sampled in You Are Sleeping is Californian poet John Harris. The sampled version omits the following introduction:
Ok. This is a poem that could only happen in Venice. It's called 'The Gospel According To John."
If you’d like to see John Harris reading his poem, he’s on YouTube presenting a version of ‘The Gospel According To John’ in 2011, which as I’m writing this has a grand total of 47 views and 0 comments. It’s a little different from the sampled version. Maybe you can suggest the significance of the elisions and differences in comments below. At my visit with John and his wife Marcia, on July 1, 2013 (they wished us a happy Canada Day) I was able to examine a annotated, typed, and paginated looseleaf copy of “The Gospel” that contained some of the revisions in that version. Here are images of those pages:


In that same visit I discovered that not only did John not know that his reading from Neighborhood Rhythms had been sampled for a popular piece of electronic music, he didn’t know that his work had been recorded to that piece of vinyl. Here is a short sample of the interview in which John is speechless at seeing Neighborhood Rhythms for the first time:
[sc_embed_player fileurl=”http://www.darrenabramson.com/wp-content/uploads/2013/07/Agape.mp3″]
The last part of this story about a story has to do with fairness, attribution, sampling and the Internet. I’m not sure if John Harris deserves money or compensation for the success of You Are Sleeping, but I’m completely certain that he deserves credit. So, I’ve posted links to this story in the places I could find where people were asking about it. In another post I may discuss John’s reaction and his own views on compensation and attribution.


